Traverse
OrientDB is a Graph database. This means that its focal point is on relationships, (that is, links), and on managing them. The standard SQL language is not sufficient to work with trees or graphs, as it lacks the concept of recursion. For this reason, the OrientDB subset of SQL implements a dedicated command for tree traversal: TRAVERSE.
Traversal operations cross relationships between records, (that is, documents, vertices, nodes, and so on). This operation runs much faster than the Relational database solution of executing a JOIN.
The main concepts in traversal are:
-
Target: Defines where you want to begin traversing records, which can be a class, cluster, or a set of records defined by their Record ID's.
You can also use any sub-query that returns an iterable
OIdentifiableobject, such as when nesting multipleSELECTandTRAVERSEqueries together. -
Fields: Defines the fields you want to traverse. If you want to traverse all fields in a document, use
*,any()orall(). -
Limit: Defines the maximum number of records to retrieve.
-
Predicate Defines an operation you want to execute against each traversed document. If the predicate returns
true, the document is returned, otherwise it is skipped. -
Strategy: Defines how you want to traverse the graph, which can be
DEPTH_FIRSTorBREADTH_FIRST.
Traversal Strategies
When issuing a traversal query to OrientDB, you can define the particular strategy for the traversal path that it uses. For instance, OrientDB can traverse down a particular branch to its maximum depth first, then backtrack, or it can traverse each child node then search the next level down. Which to use depends on the specific needs of your application.
DEPTH_FIRST Strategy
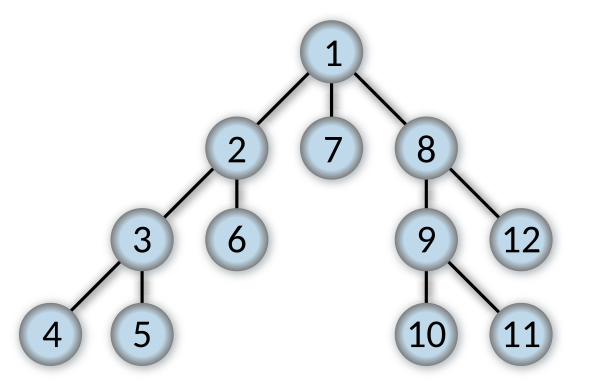
By default, OrientDB traverses to depth first. That is, it explores as far as possible through each branch before backtracking to the next.
This process is implemented using recursion. For more information, see Depth-First algorithm.
The diagram below shows the ordered steps OrientDB executes while traversing a graph using DEPTH_FIRST strategy.
BREADTH_FIRST Strategy
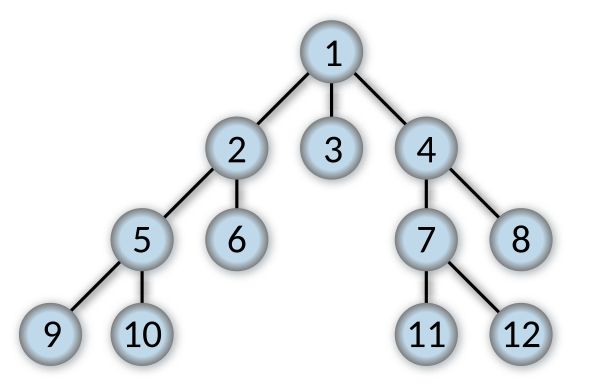
With this strategy, OrientDB inspects all neighboring nodes, then for each of those neighboring nodes in turn it inspects their neighboring nodes, which were unvisited, and so on.
Compare BREADTH_FIRST with the equivalent, but more memory-efficient iterative deepening depth first search and contrast it with DEPTH_FIRST search. For more information, see Breadth-First algorithm.
The diagram below shows the ordered steps OrientDB executes while traversing a graph using BREADTH_FIRST strategy.
Context Variables
During traversal, OrientDB provides context variables, which you can use in traversal conditions:
| Variable | Description |
|---|---|
$depth | Provides an integer indicating nesting depth in the tree. The first level is 0. |
$path | Provides a string representation of the current position as a sum of the traversed nodes. |
$stack | Provides a stack of the current traversed nodes. |
$history | Provides the entire collection of visited nodes. |
Traversal Methods
The following sections describe various traversal methods.
SQL Traverse
The simplest method available in executing a traversal is to use the SQL TRAVERSE command.
For example, say that you have a Movie class and you want to retrieve all connected from and to records up to the fifth level in depth. You might use something like this,
for (OIdentifiable id :
new OSQLSynchQuery<ODocument>(
"TRAVERSE in, out FROM Movie WHILE $depth <= 5"
)) {
System.out.println(id);
}
For more information on traversal in SQL, see TRAVERSE.